Float16 and Quantized Int8 Type
Yiqun Liu
2017-06-27
Part I, float16 - FP16, half
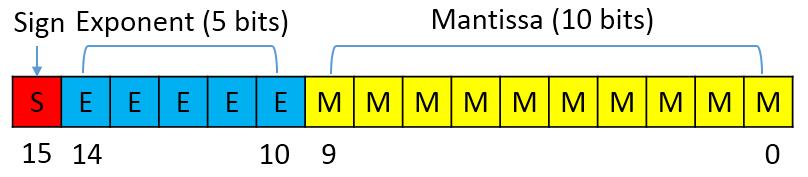
IEEE 754存储格式
- float
- 符号位: 1位
- 指数位: 8位,范围 $2^{-126}$ ~ $2^{127}$
- 尾数位:23位</small>

- half
- 符号位: 1位
- 指数位: 5位,范围 $2^{-14}$ ~ $2^{15}$
- 尾数位:10位</small>
基本类型支持
- caffe2
- 类型定义caffe2/caffe2/core/types.h
namespace caffe2 { typedef struct CAFFE2_ALIGNED(2) __f16 { uint16_t x; } float16; } // namespace caffe2 - 类型转换 caffe2/caffe2/utils/conversions.h
inline float16 cpu_float2half_rn(float f) { float16 ret; ... exponent = ((u >> 23) & 0xff); mantissa = (u & 0x7fffff); ... ret.x = (sign | (exponent << 10) | mantissa); return ret; } inline float cpu_half2float(float16 h) { unsigned sign = ((h.x >> 15) & 1); unsigned exponent = ((h.x >> 10) & 0x1f); unsigned mantissa = ((h.x & 0x3ff) << 13); ... unsigned i = ((sign << 31) | (exponent << 23) | mantissa); float ret; memcpy(&ret, &i, sizeof(i)); return ret; }</small></small>
- 类型定义caffe2/caffe2/core/types.h
基本类型支持
- CUDA include/cuda_fp16.h
- CUDA 7.5后 文档
- 类型定义
typedef struct __align__(2) { unsigned short x; } __half; typedef struct __align__(4) { unsigned int x; } __half2; - 类型转换
__device__ __half __float2half(const float a); __device__ float __half2float(const __half a); __device__ __half2 __floats2half2_rn(const float a, const float b); __device__ float2 __half22float2(const __half2 a); - 计算函数
__device__ __half __hadd(const __half a, const __half b); __device__ __half2 __hadd2(const __half2 a, const __half2 b);</small>
基本类型支持
- majel: include/majel_lite/float16.h
- Eigen: Eigen/src/Core/arch/CUDA/Half.h
- 封装了基本的+,-,*,/等运算符
- CPU上转换成float计算,GPU上调用CUDA提供的intrinsic计算
- Half-precision floating point library http://half.sourceforge.net/
- half定义
- 数值特性支持的最完整
- 优化的half2float_impl, float2half_impl实现
- 计算的优化,比如fmax、fmin
- 类型转换的其他实现 </small>
half为什么比float快?
- 硬件支持-NVIDIA GPU, Mixed-Precision Programming with CUDA 8
half2类型,两路向量半精度融合乘加指令(HFMA2),一条指令操作两个half数据__device__ __half2 __hfma2(const __half2 a, const __half2 b, const __half2 c); // a * b + c- 使用示例
__global__ void haxpy(int n, half a, const half *x, half *y) { int start = threadIdx.x + blockDim.x * blockIdx.x; int stride = blockDim.x * gridDim.x; #if __CUDA_ARCH__ >= 530 int n2 = n/2; half2 *x2 = (half2*)x, *y2 = (half2*)y; for (int i = start; i < n2; i+= stride) y2[i] = __hfma2(__halves2half2(a, a), x2[i], y2[i]); // first thread handles singleton for odd arrays if (start == 0 && (n%2)) y[n-1] = __hfma(a, x[n-1], y[n-1]); #else for (int i = start; i < n; i+= stride) y[i] = __float2half(__half2float(a) * __half2float(x[i]) + __half2float(y[i])); #endif } - Eigen内部会自动使用
half2类型计算 Eigen/src/Core/arch/CUDA/PacketMathHalf.h </small>
half为什么比float快?
- 计算库支持-NVIDIA GPU
- cuBLAS
cublasHgemm,使用FP16计算,并且作为输入输出cublasSgemmEx,使用FP32计算,输入数据可以是FP32、FP16或INT8,输出数据可以是FP32或FP16
- cuDNN
- 5.0支持FP16卷积前向计算,5.1支持FP16卷积后向计算
- TensorRT
- v1有FP16 inference卷积支持
- 其他支持FP16 gemm的计算库:nervanagpu,openai-gemm
- cuBLAS
half为什么比float快?
- 硬件支持-armv8 CPU
- 基本数据类型
float16_t - 向量数据类型
float16x8_t - 函数支持
- 基本数据类型
深度学习系统中的应用
- caffe2
if分支控制不同数据类型的计算 caffe2/operators/fully_connected_op_gpu.cctemplate <> bool FullyConnectedOp<CUDAContext>::RunOnDevice() { if (Input(0).IsType<float>()) { return DoRunWithType< float, // X float, // W float, // B float, // Y float>(); // Math } else if (Input(0).IsType<float16>()) { return DoRunWithType< float16, // X float16, // W float16, // B float16, // Y float>(); // Math } else { CAFFE_THROW("Unsupported type"); } return false; }- 只有部分Op支持float16</small>
- FullyConnectedOp, CudnnConvOp, CudnnSpatialBNOp, CuDNNPoolOp, CuDNNReluOp, CuDNNDropoutOp, MaxPoolWithIndexOp, WeightdSumOp, SumOp, CUDAAddOp </small>
深度学习系统中的应用
- caffe2
- CastOp
- caffe2/operators/cast_op.cc
- caffe2/operators/cast_op.cu
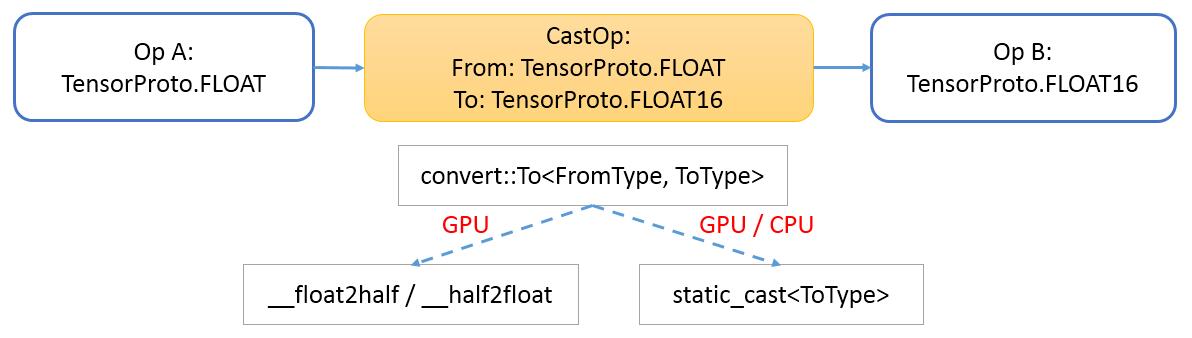
- caffe2/experiments/python/convnet_benchmark.py
data_uint8, label = model.TensorProtosDBInput( [], ["data_uint8", "label"], batch_size=batch_size, db=db, db_type=db_type ) data = model.Cast(data_uint8, "data_nhwc", to=core.DataType.FLOAT)</small>
- CastOp
PartII, Quantized int8 - Fixed point
基本类型支持
- tensorflow
- 类型定义 third_party/eigen3/unsupported/Eigen/CXX11/src/FixedPoint/FixedPointTypes.h
QInt8,QUInt8,QInt16,QUInt16,QInt32struct QInt8 { QInt8() {} QInt8(const int8_t v) : value(v) {} QInt8(const QInt32 v); operator int() const { return static_cast<int>(value); } int8_t value; };- 和Tensor数据类型DataType一一对应 tensorflow/core/framework/types.proto
- 重载这5种类型之间的基本运算符operator
- 都是转换成int32_t来计算
- 类型定义 third_party/eigen3/unsupported/Eigen/CXX11/src/FixedPoint/FixedPointTypes.h
基本类型支持
- 类型转换方法一
- 对于 $Y = W * X$
- 若 $\tilde{W} = scale_W * W$,且 $\tilde{X} = scale_X * X$
- 那么 $Y = \tilde{W} * \tilde{X} / (scale_W * scale_X)$
-
取 $scale_W = 128 / max( W_{ij} )$,那么 $-127 < \tilde{W}_{ij} < 128$
- 类型转换方法二
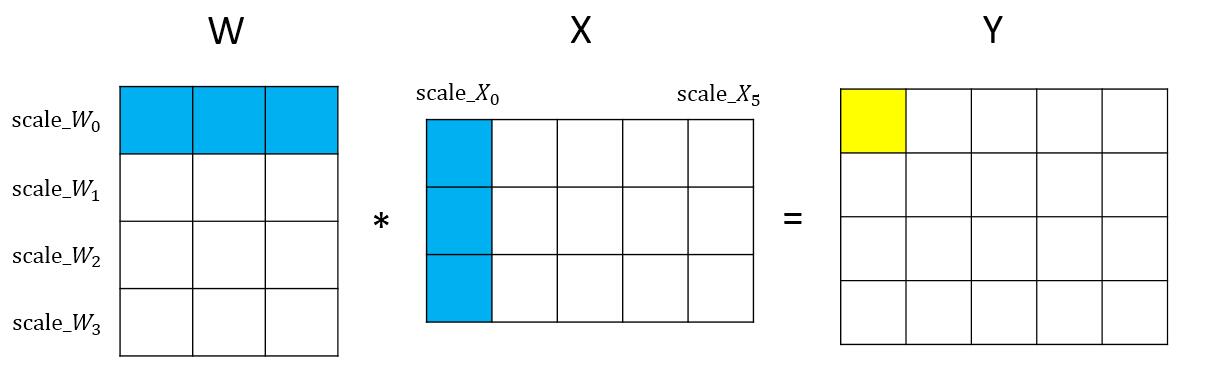
- 令 $\tilde{Y}=\tilde{W} * \tilde{X}$,则 $Y_{ij}=\tilde{Y} / {scale_W_i * scale_X_j}$
基本类型支持
- 类型转换方法-Google
- On the efficient representation and execution of deep acoustic models
- 使用
QUInt8量化,希望量化到的范围[0, 255]\(\tilde{V} = \frac{255}{V_{max}-V_{min}} * (V - V_{min})\) - 令 $Q=\frac{255}{V_{max}-V_{min}}$,恢复 \(V = \tilde{V}*Q^{-1} + V_{min}\)
- 作用于$Y=W*X$,可得 \(Y=\tilde{W}*\tilde{X}*Q_W^{-1}*Q_X^{-1} + \tilde{W}*Q_W^{-1}*X_{min} + \tilde{X}*Q_X^{-1}*W_{min}+W_{min}*X_{min}\)
为什么更快?
- 硬件支持-NVIDIA GPU, Mixed-Precision Programming with CUDA 8
- include/sm_61_intrinsics.h
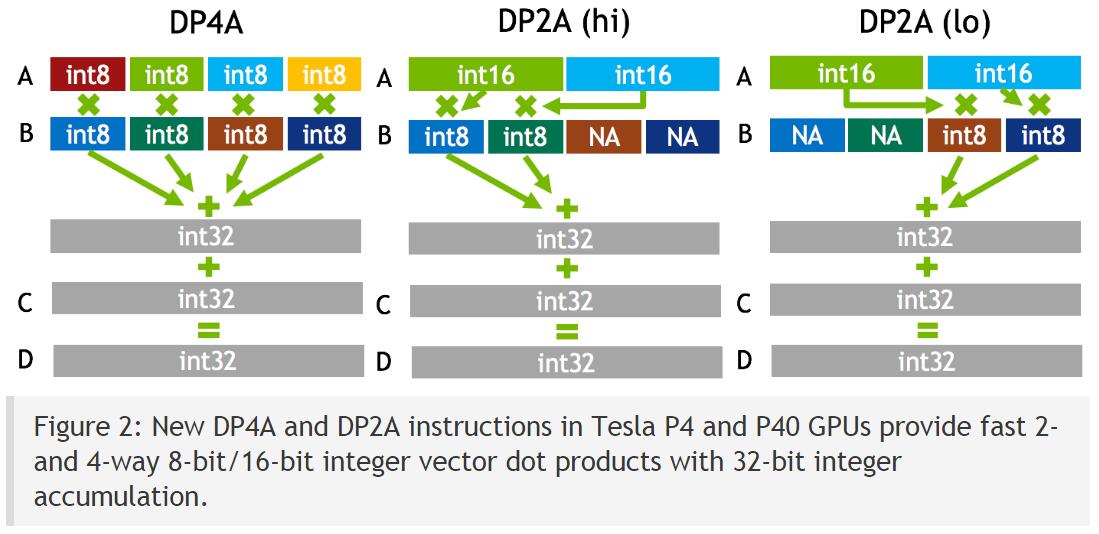
- 计算函数
__device__ int __dp4a(int srcA, int srcB, int c); __device__ int __dp4a(char4 srcA, char4 srcB, int c);
- include/sm_61_intrinsics.h
为什么更快?
- cuBLAS
- CUDA 8.0引入新接口,cublasGemm,支持INT8计算
- cuDNN
- v6增加INT8 inference支持
- TensorRT
- v2将会增加INT8 inference支持
为什么更快?
- 硬件支持-armv7a CPU
- 提供基于int8x8_t的计算
int16x8_t vmlal_s8(int16x8_t a, int8x8_t b, int8x8_t c); - 计算库
- 提供基于int8x8_t的计算
深度学习系统中的应用
- tensorflow,用TensorFlow压缩神经网络
- 使用tensorflow提供的计算图转换工具transform_graph
- quantized_weights
- quantized_nodes

- 使用tensorflow提供的计算图转换工具transform_graph
深度学习系统中的应用
- tensorflow,用TensorFlow压缩神经网络
- 使用quantize相关的op
- QuantizeV2Op, tensorflow/core/kernels/quantize_op.cc
- DequantizeOp, tensorflow/core/kernels/dequantize_op.h
- QuantizedReluOp, tensorflow/core/kernels/quantized_activation_ops.cc
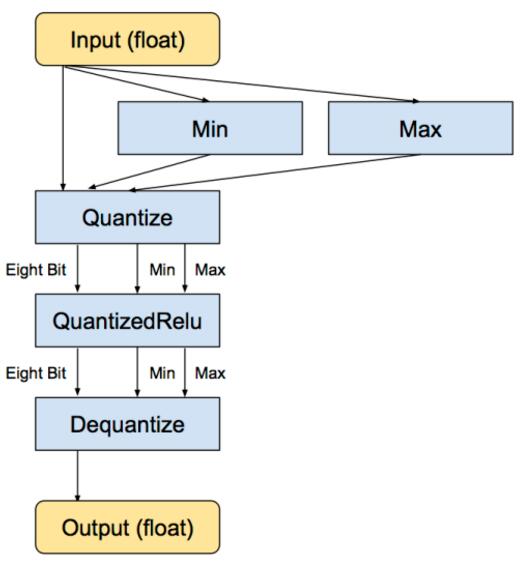
- 使用quantize相关的op